Redis知识
文章目录
redis分析,基于内存,速度快,kv数据,worker单线程,epoll多路复用解决i/o并发
拓扑模型
redis并发模型
- redis(worker单线程)通过epoll(kernel内核)读取客户端(client并发访问),知道哪些具体的客户端有数据到达
- redis访问内核读取数据 read io,一个一个去读取
- 计算
I/O 两个阶段
- 状态 epoll只获取数据到达的fd
- read、write I/O
redis 单线程worker 模型
版本5.x以前
- read c1
- 计算 c1
- write c1
- 重复1~3步,获取下一个客户端
版本6.x redis 单线程worker处理计算, 多线程I/O threads处理read、write多核CPU上可以并行
- read c1, read c2
- 计算 c1
- 计算 c2, write c1
- wirte c2
总结
- 可以通过负载均衡把相同uri指向同一台redis机器处理
- 计算worker是单线程,串行化处理,比如计算
c1、c2不分先后 - 版本6.x以前,2个客户端大概6步
- 版本6.x,2个客户端大概4步,充分利用CPU多核
客户端操作介绍
1. 使用 nc localhost 6379
|
|
2. 使用 exec 9<> /dev/tcp/localhost/6379
|
|
3. 推荐使用 redis-cli
|
|
常用数据模型
string
- 应用场景
- 计数器
incr、decr - 分布式锁
setnx - 对象 json序列化
- 计数器
bitmap
- 应用场景
- 活跃用户
- 离线统计
- 布隆过滤器,底层是bitmap,中间是hash算法转换
- 有误判率适合处理 缓存击穿
|
|
list
- 应用场景
- 点对点消息队列
- 实际生产中,目前已有
Kafka、NSQ、RabbitMQ成熟稳定 - 没有时可redis list替代
- 实际生产中,目前已有
- 栈
- 点对点消息队列
hash
- 应用场景
- 购物车
- 对象 json序列化,对象需要频繁修改,比string要优,灵活性高
set 可存储2^32 - 1 个元素(40多亿)
- 应用场景
- 好友/关注/粉丝/感兴趣的人集合 并集 差集
- 简单推荐 差集
- 随机展示
srandmember - 黑名单/白名单
sort set
- 应用场景
- 排行榜
- 评论+分页
- skiplist 实现
- 跳过一部分,减少复杂度
- 比list多一个
层的概念,越往上越稀疏 层在源码 server.h 定义常量 ZSKIPLIST_MAXLEVEL 64
持久化
持久化:性能下降
快照 rdb
- 恢复的速度快
- 缺失的多
- save
日志 aof
- 特性
- 完整
- 慢
- 冗余量, 重写
- 情况
- 每操作 完整性
- 每秒钟 os缓冲刷写,一个buffer,丢失小于一个buffer
- os 缓冲刷写,一个buffer
使用版本区别
4.x之前 rdb(默认)和aof只选一个5.x混合使用
性能测试 redis-benchmark
大概了解redis性能,对实际开发中还是有一定的作用
|
|
从结果来看, 并不是 -c 越小,性能越高,所以按实际情况调优。
可用性 AKF拆分原则 CAP定理
可用性
- 解决单点故障(主从主备)
- 一变多集群
- 机器节点数据之间是镜像的
- 解决压力大,数据量过大(分片集群、代理集群)
- 一变多集群
- 机器节点数之间据不需要复制
总结:就是生产环境一般是可以整合上述方式来使用。
CAP定理
强一致性会破坏可用性
redis默认使用弱一致性,可能会丢数据,主要做cache,问题不大。
集群一般用到 zookeeper、哨兵 技术,至少3台(奇数)以上,有2台(过半机制)达成协议(分布式一致性协议Paxos)就可以对外服务,防止脑裂。
AKF拆分原则
将redis按X,Y,Z轴划分
- X轴,水平扩展,主备冗余
- Y轴,业务划分治理,分库,不同业务连不同实例,互不影响,如:商品,活动,优惠券各自存储。
- Z轴,分片集群,同一类数据分片存储,如:商品id取模存在不同的分片上。
分片
- 客户端自己计算,比如hash算法(取模),自己去哪里获取数据
- 客户端连代理proxy,在proxy实现分片
- proxy是否有瓶颈
- 集群内部实现,分成16384个solt槽位
- 自己可以动态的rehash
- 与客户端无关,业务开发影响小
个人工作使用
大致说下工作中用到的场景,交流下
string
- 场景
- 分布式锁 领券、发送短信等
- 常规对象存储
list消息队列,开始没有人运维维护,受限技术栈,采用 swoole + redis 实现消息队列
-
解决问题
- 异步处理
- 流量削峰
-
场景
- 通过微信公众号推送海报
- 短信发送
- 用户下单,订单推送到第三方
- 用户下单支付,推送到第三方配送
hash + 管道很重要
电商网站分类等
管道可大大提升性能
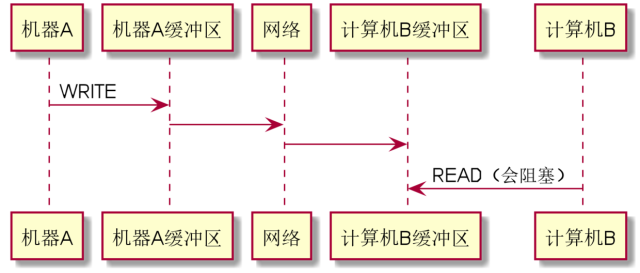
1.计算机A与计算机B的通信过程
2.假如我们在一个业务请求中,需要从Redis上获取3个不同的数据,如果我们一次一次的获取,那会怎么样?
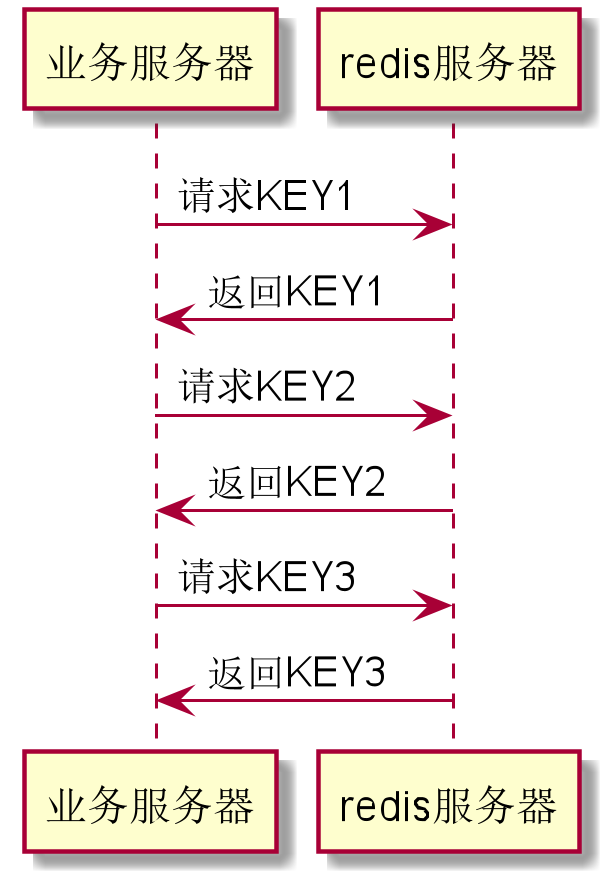
缺点:
- 每次查询,都有网络上的延迟。特别是如果Redis跟系统服务不在同一个机房,单趟来回可能要10ms,多了两趟来回,就要多20ms。
- 对于一个请求,里面需要处理20ms,对于整个请求来说,可能延迟就不止增加20ms了,毕竟服务器是多线程的,可能中途又被Linux操作系统切出去干其他事情,整个系统的并发跟吞吐立马就降下来了。
3.如果我们能够把三次请求合并成一次丢给服务器,服务器再一次性返回给我们,这不就解决问题了么?这便是Redis的管道!
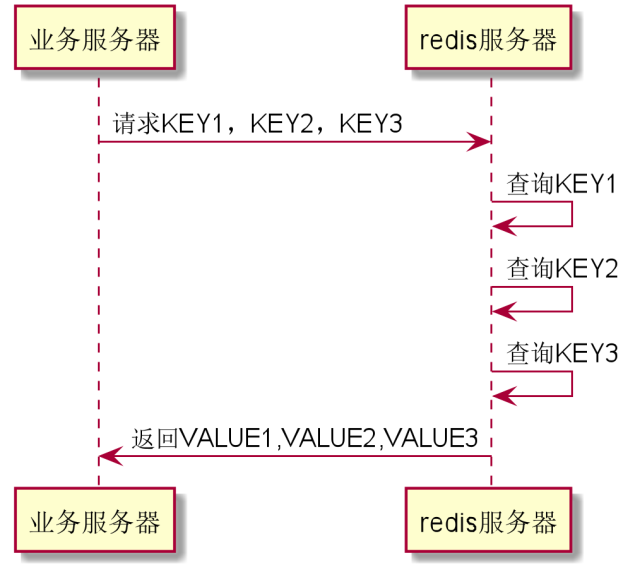
|
|
set
黑名单/白名单,每日签到数据等
redis集群的Hash Tag 配置
因为分片后redis set 类型部分命令对key进行计算时,需要将它们分配到相同的机器上去。
要求key尽可能地分散到不同机器,又要求某些相关联的key分配到相同机器。
当一个key包含 {} 的时候,就不对整个key做hash,而仅对 {} 包括的字符串做hash。部分中间代理 twemproxy 可以配置该字符串。
文章作者 小叨
上次更新 2020-04-11