2021回顾
文章目录
架构原理
互联网分层架构的本质
一个典型的互联网分层架构:
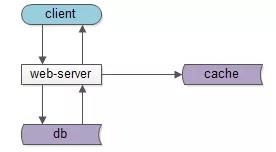
- 客户端层:典型调用方是 browser 或者 APP;
- 站点应用层:实现核心业务逻辑,从下游获取数据,对上游返回 html 或者 json;
- 数据-缓存层:加速访问存储;
- 数据-数据库层:固化数据存储;
如果实施了服务化,这个分层架构图可能是这样:
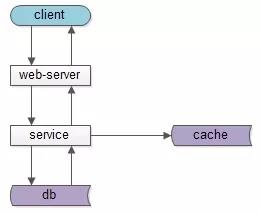
中间多了一个服务层。
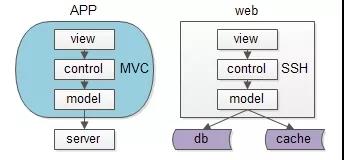
同一个层次的内部,例如端上的APP,以及 web-server,也都有 MVC 分层:
view层:展现;control层:逻辑;model层:数据;
不管是跨进程的分层架构,还是进程内的MVC分层,都是一个“数据移动”,然后“被处理”和“被呈现”的过程,一句话:互联网分层架构,是一个数据移动,处理,呈现的过程,其中数据移动是整个过程的核心。
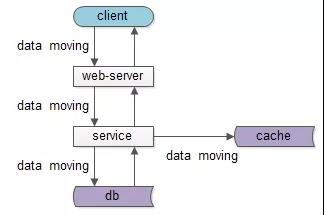
如图所示,数据处理和呈现要 CPU 计算,CPU 是固定不动的:
- db/service/web-server 都部署在固定的集群上;
- 端上,不管是 browser 还是 APP ,也有固定的 CPU 处理;
数据是移动的:
- 跨进程移动:数据从数据库和缓存里,转移到 service 层,到 web-service 层,到 client 层;
- 同进程移动:数据从 model 层,转移到 control 层,转移到 view 层;
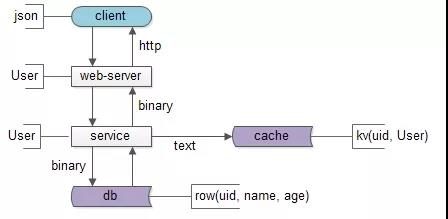
数据要移动,所以有两个东西很重要:
- 数据传输的格式;
- 数据在各层次的形态;
先看数据传输的格式,即协议很重要:
service与db/cache之间,二进制协议/文本协议是数据传输的载体;web-server和service之间,RPC的二进制协议是数据传输的载体;client和web-server之间,HTTP协议是数据传输的载体;
再看数据在各层次的形态,以用户数据为例:
db层,数据以“行”为单位存储在 row(uid, name, age);cache层,数据以 kv 的形式存储在 kv(uid -> user);service层,会把 row 或者 kv 转化为对程序友好的 User 对象;web-server层,会把对程序友好的 User 对象转化为对 HTTP 友好的 json 对象;client层:拿到的 json 对象;
结论:互联网分层架构的本质,是数据的移动。
“分层架构演进”的核心原则与方法:
- 让上游更高效的获取与处理数据,复用;
- 让下游能屏蔽数据的获取细节,封装;
总结
- 互联网分层架构的本质,是数据的移动;
- 互联网分层架构中,数据的传输格式(协议)与数据在各层次的形态很重要;
- 互联网分层架构演进的核心原则与方法:封装与复用。
互联网分层架构,为啥要前后端分离?
随着时间的推移,业务越来越复杂,改版也越来越多,,此时业务站点层 web-server 层虽有 MVC 架构,但还是会遇到痛点:
- 产品追求绚丽的效果,并对设备兼容性要求高;
- 前端展现的变化频率远远大于后端逻辑的变化频率,不管是PC,还是手机H5,还是APP端;
分离后,有单独的前端FE,来更好的处理,不太关心后端逻辑的改动。
产品需要新增 Mobile 版本,新增 APP 版本,逻辑大部分与 PC 端相同,拷贝代码多份到 Mobile、APP 端,以后逻辑稍微调整,所有端都要升级修复。
- 一旦一个服务
RPC接口有稍许变化,所有web-server系统都需要升级修改; web-server之间存在大量代码拷贝;- 一旦拷贝代码,出现一个
bug,多个子系统都需要升级修改;
如何让数据的获取更加高效快捷,如何让数据生产与数据展现解耦分离呢?前后端分离的分层抽象势在必行。
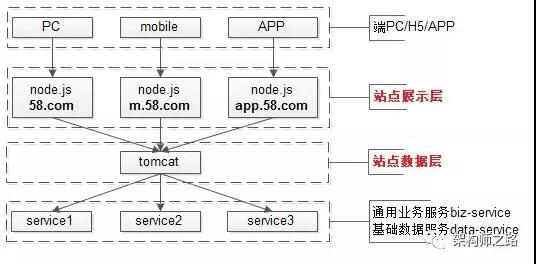
通过前后端分离分层抽象:
- 站点展示层:
node.js,负责数据的展现与交互,由FE维护; - 站点数据层:
web-server,负责业务逻辑与json数据接口的提供,由后端工程师维护;
分离好处:
- 复杂的业务逻辑与数据生成,只有在站点数据层写了一次,没有代码拷贝;
- 底层
service接口发生变化,只有站点数据层一处需要升级修改; - 底层
service如果有bug,只有站点数据层一处需要升级修改; - 站点展现层可以根据产品的不同形态,传入不同的参数,调用不同的站点数据层接口。
除此之外,其他优点:
- 产品追求绚丽结果,并对设备兼容性要求高,可以有更专业的FE对接;
- 约定好json接口后,后端和FE分开开发,FE可以用mock的接口自测,不用再等待一起联调;
于是乎,架构进化了,前后端分离了,如图所示
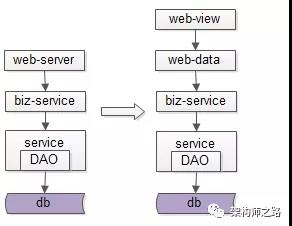
当业务越来越复杂,端上的产品越来越多,展现层的变化越来越快越来越多,站点层存在大量代码拷贝,数据获取复杂性成为通用痛点的时候,就应该进行前后端分离分层抽象,简化数据获取过程,提高数据获取效率,向上游屏蔽底层的复杂性。
另外要强调的是,是否需要前后端分离,和业务复杂性,业务发展阶段,人员素质模型有关,千万不可一概而论。
要实施前后端分离,以下四点是必须要考虑的。
第一点,SEO的考虑。
如果是 PC 端的站点,需要考虑是否要强支持SEO,前后端分离的结构,很可能对搜索引擎的spider不友好,可能影响站点的收录。
第二点,产品特性的考虑。
很多产品追求酷炫的前端效果,并且对前端兼容性要求很高,前端产品改版频率很高,那么前后端分离是有必要的。
否则,前后端分离只会带来更多系统架构的复杂性。
第三点,公司发展阶段考虑。
公司发展的初级阶段,人比较少,对产品迭代速度的要求较高,此时更多的需要一些全栈的工程师,一个人开发从前到后全搞定。如果此时实施前后端分离,将引入“联调”一说,并且增加了沟通成本比,可能导致产品迭代的速度降低。
第四点,人员技能考虑。
传统 FE 与后端工程师的合作方式, FE 工程师不需要有很深的后端功底,一旦引入前后端分离, node.js 层的前端同学需要了解更多的后端知识体系,不排除有 FE 同学对后端技能的排斥,引发人员的不稳定。
总之,前后端分离不只是一个分层架构的技术决策,和SEO、产品特性、公司发展阶段、人员知识体系相关,千万不可一概而论。
业务层,到底需不需要服务化?
随着时间的推移,系统架构并不会一成不变:
-
随着业务越来越复杂,业务会不断进行垂直拆分;
比如:信息分类网站的租房、二手、招聘等多个业务。
-
随着数据越来越复杂,基础数据服务也会越来越多;
比如:用户服务、订单服务、搜索服务、推荐服务等。
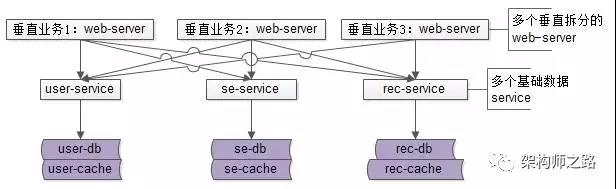
业务垂直拆分,由若干个基础数据服务:
- 垂直业务要通过多个RPC接口访问不同的基础数据服务,服务共享是服务化的特征;
- 每个基础数据服务访问自己的数据存储,数据私有也是服务化的特征;
上面架构图中的依赖关系是不是?
- 基础数据服务与存储层之间连接关系很清晰;
- 业务站点层与基础数据服务层之间的连接关系错综复杂,变成了蜘蛛网;
再举一个更具体的例子,信息分类站点列表页站点如何获取底层的数据?
- 先调用商业基础服务,获取商业广告帖子数据,用于顶部置顶/精准的广告帖子展示;
- 再调用搜索基础服务,获取自然搜索帖子数据,用于中间自然搜索帖子展示;
- 再调用推荐基础服务,获取推荐帖子数据,用于底部推荐帖子展示;
- 再调用用户基础服务,获取用户数据,用于右侧用户信息展示;
- …
如果只有一个列表页这么写还行,但如果有招聘、房产、二手、二手车、黄页等多个业务,都这么获取共性数据,而只有少部分个性数据,每次都这么一个个调用基础服务,有大量冗余、重复、每次必写的代码。
特别的,不同业务上游列表页都依赖于底层若干相同服务:
- 一旦一个服务RPC接口有稍许变化,所有上游的系统都需要升级修改;
- 子系统之间很可能出现代码拷贝;
- 一旦拷贝代码,出现一个bug,多个子系统都需要升级修改;
如何让数据的获取更加高效快捷呢?
业务服务化,通用业务服务层的抽象势在必行。
Google的锁,才是分布式锁?
早年谷歌四大基础设施,分别是 GFS、MapReduce、BigTable、Chubby。
Chubby,提供粗粒度的分布式锁服务。
典型的业务场景 具有广泛的应用场景,例如:
- GFS选主;
- BigTable中的表锁;
内核本质 Chubby本质上是一个分布式文件系统,存储大量小文件。每个文件就代表一个锁,并且可以保存一些应用层面的小规模数据。
用户可以通过打开、关闭、读取文件来获取共享锁或者独占锁;并通过反向通知机制,向用户发送更新信息。
设计之初目标
- 粗粒度的锁服务;
- 高可用、高可靠;
- 可直接存储服务信息,而无需另建服务;
- 高扩展性;
整体架构
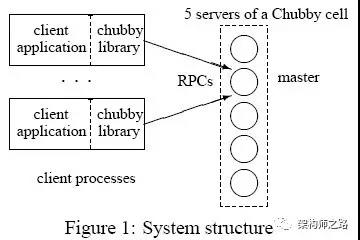
核心是这两个重要组件:
- Chubby客户端:以库的方式提供,可以通过相应API接口,申请锁服务,获取数据信息,同时保持与服务端的连接;
- Chubby服务端:服务端集群,一般由5个节点组成(至少3个节点),其中一台主节点(master),维护与客户端的所有通信;其他节点不断与主节点通信,获取用户操作;
在系统实现时,还使用了以下特性:
- 客户端缓存,以减少对主节点的访问;
- 反向通知机制,锁变化时,会反向通知客户端;
Chubby的实现关键点
- 文件系统
文件系统由许多Node组成,每个Node代表一个文件,或者一个目录。 文件系统使用 Berkeley DB 来保存每个 Node 的数据。 文件系统提供的API很少:创建文件系统、文件操作、目录操作等简易操作。
- 基于ICE的通信机制
核心就是异步,部分组件负责发送,部分组件负责接收。
- 客户端与主节点通信
- 使用长连接,连接有效期内,锁服务、客户端缓存数据均一直有效;
- 定时双向
keepalive; - 出错回调;
(1)正常情况
keepalive 会周期性发送,它有两方面功能:
一,延长租约有效期,携带事件信息告诉客户端更新;
二,执行回调,例如文件内容修改、子节点增删改、主节点出错等;
(2)客户端租约过期
客户端没有收到主节点的 keepalive,租约随之过期,将会进入一个“危险状态”。由于此时不能确定主节点是否已经终止,客户端必须主动 让本地缓存失效,同时,进入一个寻找新的主节点的阶段。
这个阶段中,客户端会轮询服务集群,访问非主节点的其他节点,当客户端收到一个肯定的答复时,它会向新的主节点发送 keepalive 信息,告之自己处于“危险状态”,并和新的主节点建立会话,然后把本地缓存中的信息刷新。
(3)主节点租约过期
主节点一段时间没有收到客户端的keepalive,会进入一段等待期,此期间内客户端仍没有响应,则主节点认为客户端失效。失效后,主节点会把客户端获得的锁,打开的临时文件清理掉,并通知各副本节点,以保持一致性。
(4)主服务器出错
主节点出错,需要内部进行重新选举,各副本节点只响应客户端的读取命令,而忽略写命令。
- 服务器集群间的一致性操作。
要解决的问题是,当主节点收到客户端请求时(主要是写),如何将操作同步到其他服务器节点,以保证数据的一致性。
(1)节点数目
一般来说,节点数为5,至少要是3。
(2)关于复制
收到客户端请求时,主节点会将请求复制到所有成员,并在消息中添加最新被提交的请求序号。副本节点收到这个请求后,获取主节点处被提交的请求序号,然后执行这个序列之前的所有请求,并把其记录到内存的日志里。
各副本节点会向主节点回复消息,主节点收到半数以上的消息(集群包含5个节点时,至少要收到3个节点),才能够进行确认,执行请求,并返回客户端。就是半数以上确认,才认为成功。
如果某个副本节点出现暂时的故障,没有收到部分消息也没关系,副本节点重新启动后,主动从主节点处获得已执行的,自己却还没有完成的日志,并进行执行。
最终,所有成员都会获得一致性的数据,正常情况下,至少有3个节点包含一致,且最新的数据。
最后,举几个Chubby使用场景的例子。
例子一,集群选主
(1)集群中每个节点都试图创建/打开同一个文件,并在该文件中记录自己的服务信息,任何时刻,肯定只有一个服务器能够获得该文件的控制权;
(2)首先创建该文件的节点成为主,并写入自己的信息;
(3)后续打开该文件的节点成为从,并读取主的信息;
例子二,进程监控
(1)各个进程都把自己的状态写入指定目录下的临时文件里;
(2)监控进程通过阅读该目录下的文件信息来获得进程状态;
(3)各个进程随时有可能死亡,因此指定目录的数据状态会发生变化;
(4)通过事件机制通知监控进程,读取相关内容,获取最新状态,达到监控目的;
总结
Google Chubby提供粗粒度锁服务,它的本质是一个松耦合分布式文件系统。开发者不需要关注复杂的同步协议,直接调用库来取得锁服务,并保证了数据的一致性。
最后要说明的是,最终Chubby系统代码共13700多行,其中ICE自动生成6400行,手动编写约8000行。
这就是Google牛逼的地方:强大的工程能力,快速稳定的实现,快速解决各种业务问题。
MySQL双主架构,原来能这么玩
MySQL为什么要使用双主架构?
MySQL最常见的集群架构,是一主多从,主从同步,读写分离的架构。通过这种方式,能够扩充数据库的读性能,保证读库的高可用,但此时写库仍然是单点。
为了保证MySQL写库的高可用,可以在一个MySQL数据库集群中可以设置两个主库,并设置双向同步,以冗余写库的方式,来保证写库的高可用。
MySQL双主架构,会存在什么问题?
如果MySQL双主架构,同时提供服务,可能会引发数据的一致性问题。因为数据的同步有一个时间差,并发的写入可能导致数据同步失败,引起数据丢失。
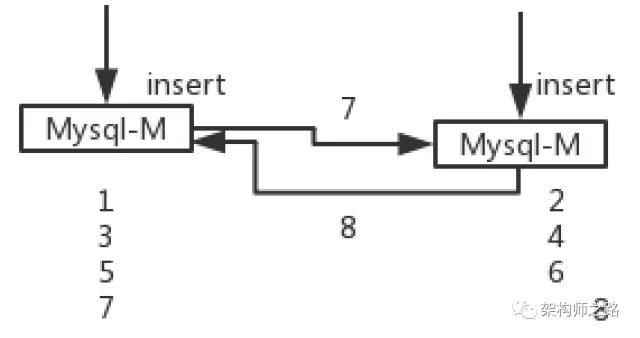
举个例子:

如上图所述,假设主库使用了auto increment来作为自增主键:
(1)两个MySQL主库设置双向同步可以用来保证主库的高可用;
(2)数据库中现存的记录主键是1,2,3;
(3)主库1插入了一条记录,主键为4,并向主库2同步数据;
(4)数据同步成功之前,主库2也插入了一条记录,由于数据还没有同步成功,插入记录生成的主键也为4,并向主库1也同步数据;
(5)主库1和主库2都插入了主键为4的记录,双主同步失败,数据不一致;
能否在MySQL层面,保证两个主库生成的主键一定不冲突呢?
可以的,只需要为两个主库的自增ID:
(1)设置不同的初始值;
(2)设置相同的增长步长;
如上图所示:
(1)两个MySQL主库设置双向同步可以用来保证主库的高可用;
(2)库1的自增初始值是1,库2的自增初始值是2,增长步长都为2;
(3)库1中插入数据主键为1/3/5/7,库2中插入数据主键为2/4/6/8,不冲突;
(4)数据双向同步后,两个主库会包含全部数据;
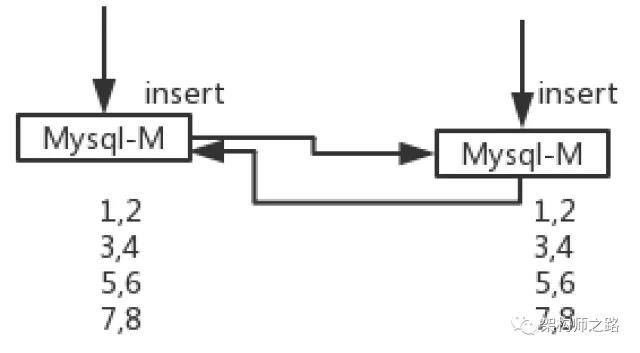
如上图所示,两个主库最终都将包含1/2/3/4/5/6/7/8所有数据,即使有一个主库挂了,另一个主库也能够保证写库的高可用。
上述方案,依赖与数据库的配置,能不能由应用程序,来保证数据的一致性呢?
答案是肯定的,应用程序使用统一的ID生成器,可以保证ID的生成不冲突。
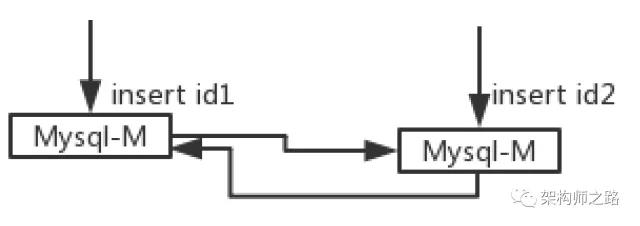
如上图所示,调用方插入数据时,带入全局唯一ID,而不依赖于数据库的auto increment,也能解决这个问题。
画外音:如何生成全局唯一趋势递增的ID,不展开。
引发不一致的根本原因,是保证高可用的两个主库都对外提供服务,如果只有一个主库对外提供服务,另一个主库平时不提供服务,仅仅在主库挂了的时候提供服务,能否消除上述数据不一致呢?
答案是悲观的,仍然不行。
使用 VIP + Keepalived的方式保证数据库主库的高可用,平时只有一台主库提供服务,也可能出现数据不一致。
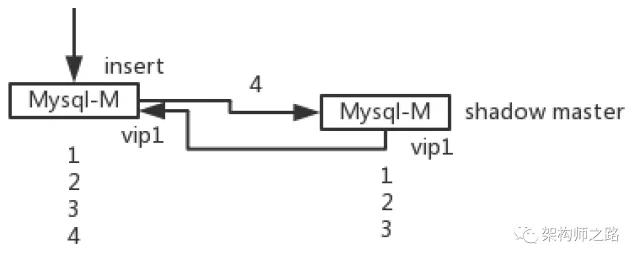
如上图所示:
(1)两个MySQL主库设置双向同步可以用来保证主库的高可用;
(2)只有主库1对外提供写入服务;
(3)两个主库设置相同的虚IP,在主库1挂掉或者网络异常的时候,虚IP自动漂移,备用主库顶上,保证主库的高可用;
切换过程中,由于虚IP没有变化,所以切换过程对调用方是透明的,但在极限的情况下,仍可能引发数据不一致。
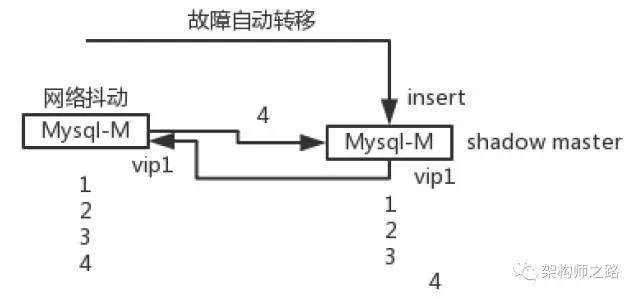
如上图所示:
(1)两个MySQL主库设置双向同步,可以用来保证主库的高可用,并设置了相同的虚IP;
(2)网络抖动前,主库1对上游提供写入服务,插入了一条记录,主键为4,并向备用主库2同步数据;
(3)突然主库1网络异常,keepalived检测出异常后,实施虚IP漂移,备用主库2开始提供服务;
(4)在主键4的数据同步成功之前,主库2插入了一条记录,也生成了主键为4的记录,结果导致数据不一致;
有没有办法缓解上述问题呢?
虚IP漂移,双主同步延时导致的数据不一致,本质上,需要在双主同步完数据之后,再实施虚IP偏移。
使用内网DNS探测,缓解上述问题:
(1)使用内网域名连接数据库,例如:db.kg.org;
(2)主库1和主库2设置双主同步,不使用相同虚IP,而是分别使用ip1和ip2;
(3)一开始db.kg.org指向ip1;
(4)用一个小脚本轮询探测ip1主库的连通性;
(5)当ip1主库发生异常时,脚本delay一个x秒的延时,等待主库2同步完数据之后,再将db.kg.org解析到ip2;
(6)应用程序以内网域名进行重连,即可自动连接到ip2主库,并保证了数据的一致性;
画外音:本质上,这是一个可用性与一致性的折衷。
总结
MySQL主库高可用,主库一致性,一些小技巧:
(1)双主同步是一种常见的保证写库高可用的方式;
(2)**设置相同步长,不同初始值,**可以避免auto increment生成冲突主键;
(3)不依赖数据库,业务调用方自己生成全局唯一ID是一个好方法;
(4)双主保证写库高可用,只有一个写库提供服务,并不能完全保证一致性;
(5)内网DNS探测,可以实现在主库1出现问题后,延时一个时间,再进行主库切换,以保证数据一致性,但牺牲了几秒钟的高可用;
文章作者 小叨
上次更新 2022-01-12